The title is a misdirection. The token counts may be higher, but the cost-per-task may not be for a given intelligence level. Need to wait to see Artificial Analysis' Intelligence Index run for this, or some other independent per-task cost analysis.
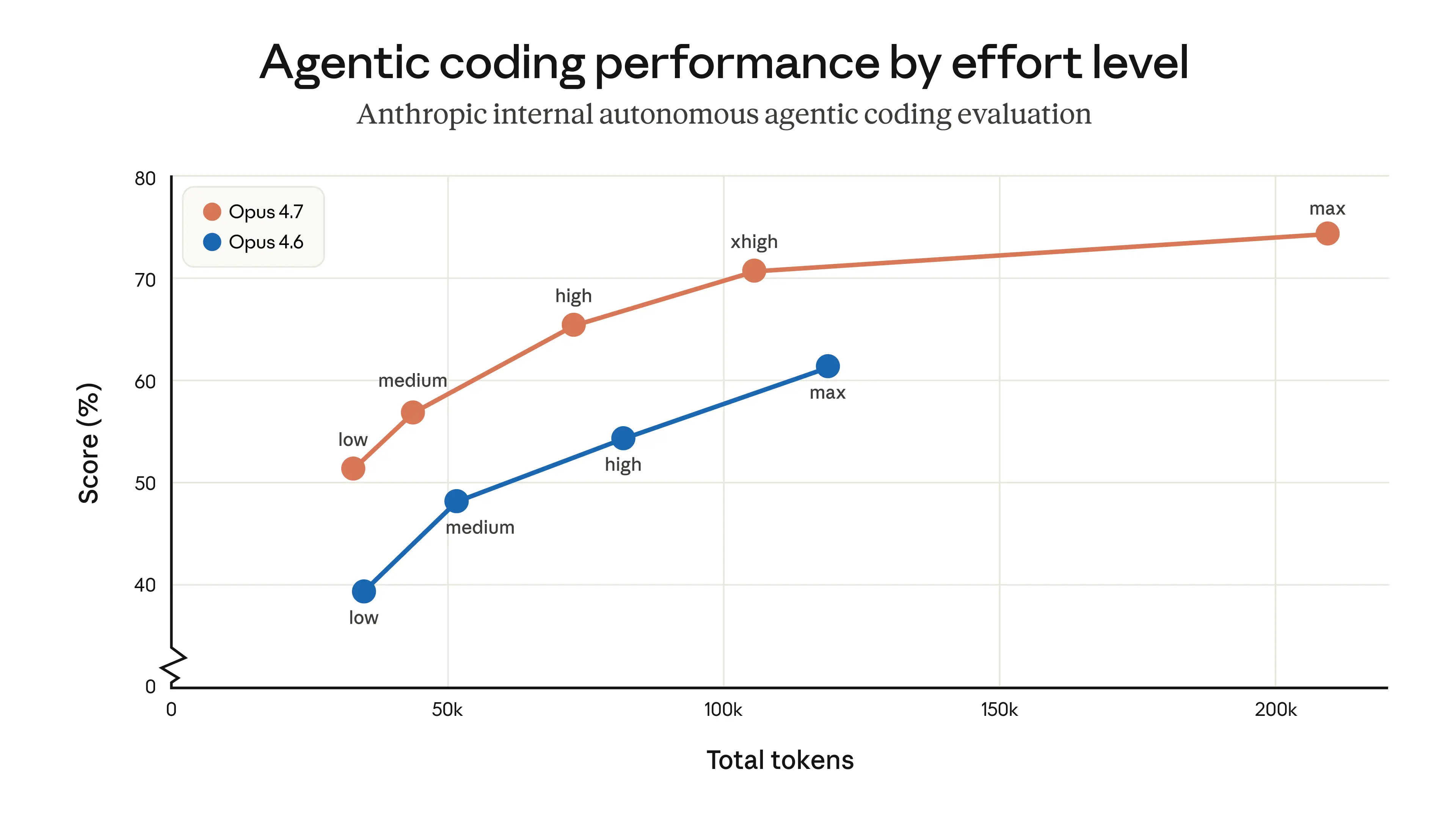
The final calculation assumes that Opus 4.7 uses the exact same trajectory + reasoning output as Opus 4.6.
I have not verified, but I assume it not to be the case, given that Opus 4.7 on Low thinking is strictly better than Opus 4.6 on Medium, etc., etc.
I ran an internal (oil and gas focused) benchmark yesterday and found Opus 4.7 was 50% cheaper than Opus 4.6, driven by significantly fewer output tokens for reasoning. It also scored 80% (vs. 60%).
yep, ran a controlled experiment on 28 tasks comparing old opus 4.6 vs new opus 4.6 vs 4.7, and found that 4.7 is comparable in cost to old 4.6, and ~20% more expensive then new 4.6 (because new 4.6 is thinking less)
A fun conspiracy theory I have is that Mythos isn’t actually dangerous in any serious sense. They just can’t reliably serve a 10T model. So they have to make up a reason to limit customers.
(Submitted title was "Claude Opus 4.7 costs 20–30% more per session". We've since changed it to a (more neutral) version of what the article's title says.)
I think it's time to have previous titles show as a edit * icon that can show the previous title.
This is not the first time where the more neutral (which imo is better) has caused me to be confused why everyone is saying something different in the comments.
That's probably too much ceremony for HN but petercooper made a really nice HN title edit tracker which is probably still running. Let me see if I can dig it up for you...
im running some experiments on this but based on what i have seen on my own personal data - I dont think this is true
"given that Opus 4.7 on Low thinking is strictly better than Opus 4.6 on Medium, etc., etc.”
Opus 4.7 in general is more expensive for similar usage. Now we can argue that is provides better performance all else being equal but I haven’t been able to see that
Very unlikely that the article is wrong. the 4.7 intelligence bump is not that big, plus most of the token spend is in inputs/tool calls etc, much of which won't change even with this bump.
My workloads generate ~5x more output than input, and output tokens cost 5x more per token... output dominates my bill at roughly 25x the cost of input. (Even more so when you consider cache hits!)
If Opus 4.7 was more efficient with reasoning (and thus output), I'd likely save considerable money (were I paying per-token).
{kind=link}
The final calculation assumes that Opus 4.7 uses the exact same trajectory + reasoning output as Opus 4.6. I have not verified, but I assume it not to be the case, given that Opus 4.7 on Low thinking is strictly better than Opus 4.6 on Medium, etc., etc.